La technologie géospatiale et l’environnement infonuagique natif
22 novembre 2021
Le secteur de la technologie géospatiale a un problème : les données. Pendant le développement de l’industrie géospatiale à la fin des années 70 et dans les années 80, le stockage et le traitement étaient de plus en plus problématiques. Les microordinateurs DEC VAX et, plus tard, les postes de travail IBM et Sun, se sont avérés nécessaires pour le traitement informatique des données. Il est donc peu surprenant qu’aujourd’hui, la communauté géospatiale ait toujours présumé que nous avions un problème de données. Un problème de « mégadonnées ».
Cependant, la bonne nouvelle est que, au fil des années, le secteur est passé de la simple collecte et la création d’énormes volumes de données à l’analyse des données. De plus, les données géospatiales représentent un type de données clé dans l’ensemble de l’industrie de la technologie de l’information (TI), qui dévoile des informations que les autres données ne possèdent pas. Par conséquent, les innovations en stockage, en traitement et en apprentissage machine, comme celles offertes par les plateformes de données infonuagiques actuelles, permettent d’accommoder les données géospatiales et les nuances créées par la collecte de données de la surface de la Terre.
Entrepôts de données ou lacs de données?
Pour les utilisateurs de l’information géospatiale, le stockage et l’analyse des données structurées et non structurées donnent lieu à une discussion sur la meilleure façon de faire les deux dans un environnement infonuagique natif. Les entreprises qui exploitent actuellement des données géospatiales ont créé des entrepôts de données. Cela a entraîné la création de silos pour chaque type de données, ce qui ne s’est pas avéré être un moyen efficace pour les analyses. Certaines de ces données proviennent de capteurs en temps réel à haute vélocité qui recueillent des données au sujet de la circulation, de la météo, des courants de ruissellement des eaux et d’autres sources devenues inutiles au sein du cadre architectural des entrepôts de données. Comme il est décrit par les auteurs de Databricks dans un récent blogue :
Bien que les entrepôts étaient merveilleux pour les données structurées, un grand nombre d’entreprises modernes doivent gérer des données non structurées, des données semi-structurées ainsi que des données très variées à vélocité et à volume élevés. Les entrepôts de données ne sont pas appropriés pour plusieurs de ces utilisations et ils ne sont certainement pas les plus rentables.
Par conséquent, les entreprises ont commencé à chercher une solution pour le stockage de plusieurs types et formats différents de données géospatiales dans un seul dépôt interopérable, et c’est à ce moment que le concept de lac de données est apparu.
Cela signifiait que les données vectorielles, comme KML, shapefile, WKT et GeoJSON, ainsi que les données matricielles, comme GeoTiff, et d’autres entités, comme les adresses, devaient être géocodées.
Encore une fois, Databricks signale quelques défis :
Bien qu’ils soient appropriés pour stocker les données, les lacs de données n’offrent pas certaines fonctionnalités critiques : ils ne prennent pas en charge les transactions et ne contrôlent pas la qualité des données. En outre, leur manque d’uniformité et d’isolation signifie qu’il est pratiquement impossible de mélanger les ajouts et les lectures ainsi que les tâches de traitement par lot et de diffusion. Pour ces raisons, plusieurs des promesses faites par les lacs de données ne se sont pas matérialisées.
Le passage des entrepôts de données aux lacs de données a engendré un nouveau problème.
La mise en œuvre ainsi que la gestion de ces types d’infrastructure et de plateformes sur les lieux demandaient tellement de temps de la part des services commerciaux et de TI, qu’il leur restait peu de temps pour optimiser la plateforme et développer des cas d’utilisation essentiels pour s’adapter à l’évolution rapide des besoins commerciaux. Il fallait trouver une autre solution.
La technologie géospatiale au sein de la TI traditionnelle
Dans de nombreuses organisations — qu’il s’agisse d’entités gouvernementales traditionnelles pourvues d’importants services de SIG ou d’entreprises qui exploitent les données de localisation pour des applications commerciales clés, telles que la souscription d’assurances ou le choix d’un site de vente au détail —, les données géospatiales sont souvent gérées par le personnel du service informatique. Lorsque nous parlons de gouvernance des données pour les données spatiales, un débat est soulevé pour déterminer si le système d’archivage devrait être la plateforme SIG, qui centralise toutes les données géospatiales, ou le système commercial d’où proviennent les données. En utilisant l’exemple de l’assurance, est-ce que le système informatique d’entreprise qui gère les données sur les polices et les réclamations géolocalisées par adresse devrait être le principal entrepôt de données et ainsi être capable de prendre en charge les données géospatiales?
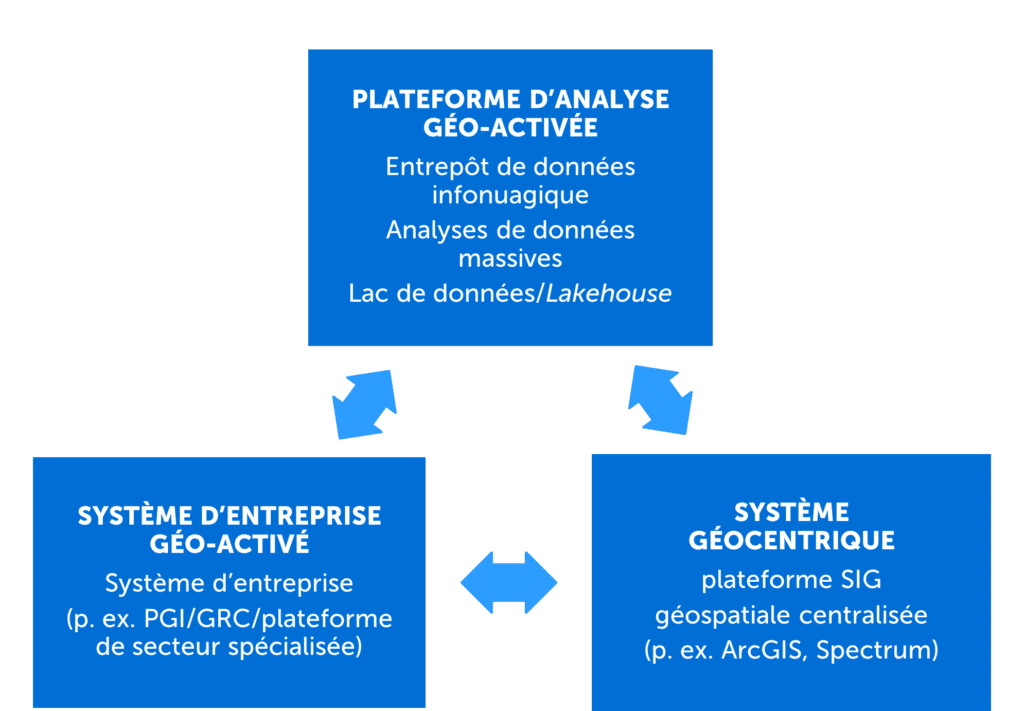
En gardant cette question à l’esprit, les fournisseurs de logiciels géospatiaux doivent commencer à adopter un modèle qui est « créé une seule fois et utilisé partout » (“write once deploy anywhere”). Ces fournisseurs de solution doivent pouvoir mettre en œuvre ou intégrer leurs capacités à l’extérieur de leur plateforme SIG centralisée et, par conséquent, géo-activer d’autres applications. Bien que la géo-activation des systèmes commerciaux soit déjà assez répandue, la géo-activation des prochaines générations de plateformes, comme les plateformes infonuagiques d’analyse de données massives, devient nécessaire, surtout lorsque l’on constate que les analyses de site sont devenues un élément important de toutes les tâches analytiques. Cela devient indispensable, qu’il s’agisse d’une solution pour l’analyse de données massives pour le traitement de grands volumes ou d’une intégration à grande échelle en temps réel qui nécessite la disponibilité et l’élasticité d’un amas Kubernetes infonuagique natif, par exemple (reportez-vous à la Figure 1).
Commencez votre géo-activation »
Agilité commerciale
Pendant leur processus de modernisation numérique, plusieurs entreprises migrent leurs entrepôts de données vers des plateformes d’analyses de données massives et infonuagiques natives, telles que Databricks, Snowflake et Google Big Query, dans le but d’obtenir une plus grande agilité commerciale. Les services de TI doivent démontrer la valeur temporelle, la souplesse du processus en matière d’économies pour l’infrastructure ainsi que l’accès à des plateformes et à des outils avancés qui peuvent gérer le déluge de données. Cette logique est fondée sur leur capacité à adopter des analyses avancées et l’apprentissage machine pour une variété de cas d’utilisation, que ce soit pour le traitement de gros lots ou pour l’intégration du modèle opérationnel en temps réel.
Ces plateformes géo-activées de prochaine génération, comme Databricks, qui adoptent le paradigme de lakehouse, représentent un outil très puissant, non seulement pour les scientifiques de données, mais aussi pour les directeurs des systèmes d’information (DSI) qui veulent obtenir des résultats plus rapides pour les cas d’utilisation complexes. Un lakehouse comporte les avantages d’un entrepôt de données et d’un lac de données en offrant la possibilité d’effectuer des demandes d’analyse sur tous les types de données (structurées et semi-structurées, par exemple) sans avoir besoin d’un schéma de base de données traditionnel. Selon Databricks, le stockage est découplé de l’environnement informatique qui utilise des amas séparés. Le fait de pouvoir produire un amas Databricks en quelques minutes et d’exécuter un modèle à l’échelle, sans devoir maintenir l’architecture matérielle et logicielle sous-jacente, procure de l’autonomie et de la souplesse aux processus commerciaux.
Exploiter les avantages inhérents de la technologie et des données géospatiales
Ces environnements doivent aussi être en mesure d’exploiter les attributs géospatiaux au sein d’une architecture lakehouse et d’optimiser leur traitement distribué et leur extensibilité. Qu’il s’agisse de dossiers de clients, d’actifs de l’entreprise, de renseignements de suivi, comme GPS ou des traces d’IdO, les entreprises accumuleront des téraoctets de données, presque toutes marquées de coordonnées géographiques, comme la latitude et la longitude.
Bien que certains fournisseurs qui adhèrent à une architecture lakehouse prennent en charge certaines fonctionnalités d’interrogation géospatiale, elles ne sont pas comparables à l’étendue des capacités offerte par une plateforme SIG ou géocentrique traditionnelle. Même si le déplacement des données entre le système lakehouse et les SIG au moyen de GeoETL peut fonctionner pour des volumes de données plus petits, cela n’est pas le cas pour les données dont le volume et la vélocité sont plus élevés. Lorsque les volumes de données augmentent, il s’avère rapidement insoutenable de déplacer les données entre les domaines informatiques, tant du point de vue de la science des données que de l’informatique.
Heureusement, quelques-unes de ces plateformes comprennent certaines capacités géospatiales. Les fournisseurs géospatiaux commencent maintenant à offrir des extensions, telles que celles offertes par Big Query UDF de CARTO ou la suite de SDK infonuagiques natives de Precisely, qui prennent en charge de nombreuses technologies, telles que Databricks, Snowflakes et Kubernetes. Ces fournisseurs offrent habituellement des capacités géospatiales vectorielles et parfois matricielles, mais un plus grand nombre de fonctions géospatiales, comme le géocodage, la validation des adresses et le routage, sont intégrées dans ces types d’environnement. Une telle intégration rehausse la performance et la souplesse pour éviter d’avoir à transférer les données, tout en optimisant la puissance de traitement distribué sous-jacent du nuage.
Rappel à la réalité
Aujourd’hui, de nombreuses solutions d’intelligence économique (p. ex. Tableau et Cognos) incluent la visualisation de carte et au moins une analyse spatiale rudimentaire comme fonctionnalités. Des bases de données populaires (p. ex. Oracle, Microsoft Azure et IBM Db2) offrent un soutien considérable pour les systèmes géospatiaux de coordonnées et primitifs, en plus d’une analyse spatiale. Puisque 85 % des données d’entreprise comprennent un élément géospatial, il existe un besoin indéniable en plateformes géocentriques, comme les SIG, les solutions d’intelligence économiques géo-activées qui soutiennent les utilisateurs finaux et les lakehouses de données élastiques requis par les environnements informatiques des entreprises.
Par conséquent, la technologie et les données géospatiales sont devenues un outil essentiel dans l’arsenal de l’utilisateur professionnel. Le secteur géospatial pourrait nécessiter la collaboration avec une entreprise qui possède les connaissances et l’expérience requises pour aborder les cas d’utilisation de données et l’architecture de solution, qui se trouvent à l’intersection des analyses géospatiales avancées et de l’architecture infonuagique moderne. Korem est votre intégrateur technologique géospatial qui connaît parfaitement le nuage.
- Partager :





